事先声明:以下故事基于真实事件而改编,如有雷同,纯属巧合~
眼下这位正襟危坐的男子,名为小竹,他正是本次事件的主人公,也即将成为熊猫集团的被告,嗯?这究竟怎么一回事?欲知内幕如何,且听下回分解……,啊不对,欲知内幕如何,还需将时间拨回三周之前.......
哒、哒、哒,那是高跟鞋接触地板发出的碰撞声,而此时慵懒瘫坐在工位上的小竹浑然不知,身后有着一位女子正在快速接近,只见此女身穿黑丝色职业装,定睛一看,原来正是熊猫集团董事长的千金!
一声呼喊突然打破了正在悠哉游哉般摸鱼的小竹:
小竹小竹,这里有个紧急的商城项目,你快来搞一下,三周后要上线!
一个完整项目,三周时间就要上线!!怎么办?为了按期交付出产品,小竹遵循着“能跑就行”的原则,动用了他的CV大法,平均日码3W行!不到三周时间,小型商城项目快速完工。
需求验收时,小竹发现每点一个功能,浏览器都要转半分钟圈圈,此时客户的眉头紧皱,小竹见状急忙开口道:
王总,虽然看着慢了点,可又不是不能用!三周时间还要啥自行车,你说是吧?
于是就这样,产品在客户的万般不满下顺利交付,小竹还贴心的送上了“上线部署”一条龙服务。
视角拉回三周后的今天……
王总再次来到了公司,并站在小竹身前大声质问道:“昨晚这事必须得给我一个解释!否则你等着被我起诉吧!”
嗯?具体咋回事?哦~,原来是上线的商城项目,突然遇到了并发,导致王总损失197.83元!
咳咳,看到这里,不是Java开发的看官可以撤了,后续内容已经雨女无瓜~
OK,下面开始本文的正式内容,看完如果有所收获,请记得点赞、收藏、关注三连支持一下噢~
一、真实事件的来龙去脉
开局我提到一句话,上述故事基于真实事件改编,其实具体情况和故事差不多,这是来自于一位在微信找我解决Bug的读者,为了方便称呼,这里我们将其化名为:小帅。
小帅是一位工作近三年的全栈开发,任职于一家小的项目型外包公司,平时工作就是负责开发Boss从外部承接过来的项目,由于近期项目过多,所以CV大法用上头了,写代码的技巧只有一个:梭哈!
正因如此,给某位客户写的项目突然遇到了并发,造成做项目的老板出现损失,先来看问题:

做的是个商城类型的项目,但平台内所有的交易,没有直接对接支付渠道,而是设计了“平台币”这种形式。用户可以通过常用支付渠道充值“平台币”,接着可以用“平台币”购买商品;同时,为了资金的合理性,“平台币”也可以反向提现,如提现到微信、支付宝、银行卡。
PS:实际项目中,现金和平台币的比率并非1:1,下面为了便于说明,我们假设为1:1。
所以目前的交易种类,总共有“下单、提现”这两种(实际还有其他种类,这里不展开),数据库里也有几张关于交易的表,最核心的是有张账户表,省略其他业务字段如下:
账户表:{账户ID、账户名、账户余额}
此时问题来了,由于是接过来的小项目,开发时的第一准则追求的是:速度,只要需求能实现,质量、安全啥的都不重要,所以“小帅”在开发项目时,结合MVC思想与三层架构模型,将整个项目分为了:
- 数据层:就是mapper/dao包,提供操作数据库表的接口;
- 业务层:基于数据层的接口,结合实际业务,实现业务方法;
- 表现层:调用业务层的方法,对外提供可访问的网络接口。
这个结构相信大家应该再熟悉不过了,接着小帅在业务层写了“提现、下单”两个方法,如下:
// --------------数据层---------------
public interface AccountMapper {
// 修改账户表的接口
int update(Account account);
// 根据账户名查询账户信息的接口
Account getAccountByName(String accountName);
// 省略其他接口......
}
// --------------业务层---------------
public class AccountServiceImpl implements IAccountService {
@Autowired
private AccountMapper accountMapper;
// 提现的业务方法
public boolean cashWithdrawal(String accountName, int type,
String target, BigDecimal money){
// 先根据账户名查询出账户信息
Account account = accountMapper.getAccountByName(accountName);
// 省略提现的其他前置处理,如余额检查、交易方式处理......
// 调用数据层update方法,用余额减去提现金额,然后修改数据表
account.setBalance(account.getBalance().subtract(money));
int rowNumber = accountMapper.update(account);
// 省略提现的其他后置处理,如提现消息通知、流水记录......
if (rowNumber > 0){
return true;
}
return false;
}
// 下单的业务方法
public boolean placeAnOrder(Order order, String accountName){
// 先根据账户名查询出账户信息
Account account = accountMapper.getAccountByName(accountName);
// 省略下单其他的前置处理,如库存检测、账户余额查询......
// 调用数据层update方法,用余额减去订单金额,然后修改数据表
account.setBalance(account.getBalance().subtract(order.getMoney()));
int rowNumber = accountMapper.update(account);
// 省略提现的其他后置处理,如物流通知、流水记录......
if (rowNumber > 0){
return true;
}
return false;
}
// 省略其他方法......
}为了避免业务逻辑的干扰,这里抽取了核心代码,AccountServiceImpl类中有两个方法:
- cashWithdrawal()提现,参数依次为账户名、提现类型、目标账户、提现金额;
- placeAnOrder()下单,参数依次为订单实体对象,下单用户对应的账户名。
其他方面无需关心,重点关注两个方法中都有的一行代码:
int rowNumber = accountMapper.update(account);提现、下单,都是依靠数据层的修改方法,来减去相应账户的余额,搞明白这点后,来思考一个问题:
一个用户的余额为100元,同时触发下单100元、提现100元操作,会发生什么?
相信研究过并发编程的小伙伴,就应该能推断出问题,在之前的《一个请求的网络之旅》中,曾提到过一个概念:一个客户端的请求来到服务端后,会分配一条对应的线程来处理。为此,下单、提现两个请求,也会对应两条线程,两条线程同时执行update()减100元余额的操作,此时钱会被扣两次,余额最终变成-100元!
理解上述这段话后,接着再来说说“小帅”当时遇到的情况,他所遇的情况也十分类似,某一天夜里,平台的一个用户在疯狂重复“充值、下单、提现、退款”这个动作,嗯?平台是如何察觉出来的呢?这是因为项目的客户在查看交易流水时,发现流水记录里,同一个用户出现大量交易记录,所以才发觉了异常。
PS:因为是小的外包项目,平台用户量不大,所以流水记录里才显得特别突出。
客户当时把问题反馈过来之后,小帅介入排查,回溯该用户的交易流水,结果发现是因为这个用户,在机缘巧合之下,用47.83元买了一个商品,同时又提现了47.83元(当时余额只有50元左右),然后或许是该用户闲的没事做,就利用这个漏洞开始疯狂薅羊毛……
根据流水记录来推断,这个用户当时的操作是这样的:
- ①先通过充值入口,用微信充值了50元,得到了50个平台币;
- ②再开两个网页窗口,同时触发下单50元、提现50元的操作;
- ③如果提现成功,下单失败,则再通过充值入口,重新充50元进来;
- ④如果提现失败,下单成功,则在订单中心里面,对相应订单发起退款;
- ⑤如果提现成功,下单成功,则回到前面的第②步重复操作。
相信大家应该能理解这个羊毛党的薅法,不过为何会出现提现、下单,其中一方失败的现象呢?因为该用户是通过手动点击,模拟同时触发下单、提现操作,而网络延迟是不可控因素,有时这两个请求,会一前一后的来到服务端,当前一个请求把余额扣掉之后,后一个请求就过不了“余额检测”步骤,无法进行扣款,从而导致提现/下单失败。
这个用户在后台的流水高达上百条,不过因为提现、退款都需要时间,所以加上最开始的一次,总共也就成功了四次,分别为47.83、50、50、50元,为此项目方的老板,在一夜时间里总共被薅197.83元!
得亏这小子不会编程,否则写个程序疯狂调用,老板的房子都能被薅走一套~
有人也许会好奇:为什么这小子不直接充1w甚至更大的金额,然后进行操作呢?我的猜测是:可能害怕被发现,然后中途冻结他的账户,怕充进去就真提不出来了~
二、并发漏洞的修复方案
经过上一阶段的叙述,相信大家对本次事件的来龙去脉,都有了全面认知,那又该如何修复这个并发漏洞呢?下面一起来聊聊这个话题。
2.1、传统的全局锁

当我看到小帅这个问题后,我告诉他要加锁,确保同一时间内,只能有一条线程修改账户余额,这样就不会出现前面的并发问题:

然后我给他演示了一下ReetrantLock的用法,伪代码如下:
// 先定义一把全局的lock锁
private ReetrantLock lock = new ReetrantLock();
// 提现方法
public boolean cashWithdrawal(String accountName, int type,
String target, BigDecimal money){
// 用finally来保证锁的释放
try{
// 获取锁
lock.lock();
// 模拟余额检测代码……
// 模拟修改余额代码……
// 释放锁
lock.unlock();
} finally {
// 确保异常也能释放锁
lock.unlock();
}
// 省略其他代码......
}
// 下单方法
public boolean placeAnOrder(Order order, String accountName){
// 用finally来保证锁的释放
try{
// 获取锁
lock.lock();
// 模拟余额检测代码……
// 模拟修改余额代码……
// 释放锁
lock.unlock();
} finally {
// 确保异常也能释放锁
lock.unlock();
}
// 省略其他代码......
}这个示例也特别简单,无非定义了一个lock全局变量,这意味着是一把全局锁,两个操作余额的方法,同时被调用时,两条线程竞争同一把锁,只会有一个成功,另一个会阻塞。成功的线程去修改账户余额,修改完成并释放锁后,另一条线程会拿到锁,可是由于上条线程已经把余额扣掉了,第二条线程就无法通过“余额检测”。
听着上述回答,是不是感觉问题解决了?可是小帅当时又补了一句:
我在多个业务类里,都有直接调用AccountMapper来修改账户余额!
此时怎么做?第一种做法是把“修改余额”操作单独抽成一个方法,然后在其中使用ReetrantLock加锁,其他所有要修改余额的业务,都调用这个方法来完成。不过这种做法显然不行,毕竟他这个项目已经交付了,前面的“屎山”已经堆起来了,想要单独抽出一个方法,会涉及很多处代码变更。
来看看第二种做法,有经验的小伙伴应该猜到了,怎么做呢?用synchronized关键字,将AccountServiceImpl.class作为锁对象,所有涉及到“修改余额”的地方,都加上这个锁,如:
// 提现方法
public boolean cashWithdrawal(String accountName, int type,
String target, BigDecimal money){
// 使用synchronized全局锁
synchronized (AccountServiceImpl.class){
// 模拟余额检测代码……
// 模拟修改余额代码……
}
// 省略其他代码......
}
// 下单方法
public boolean placeAnOrder(Order order, String accountName){
// 使用synchronized全局锁
synchronized (AccountServiceImpl.class){
// 模拟余额检测代码……
// 模拟修改余额代码……
}
// 省略其他代码......
}至于为什么用AccountServiceImpl.class作为锁对象,就可以实现不同类中的“全局锁”,如若不了解的小伙伴,可以去看:《剖析Synchronized关键字-应用方式与锁类型》这一小节。
其实还有第三种方法,就是定义一个static静态的全局ReetrantLock锁,但不说了。
这些方式听起来是不是很不错?如果你点头,那可就大错特错了!!!
原因是什么?因为这是传统意义上的全局锁,虽说能锁住同一个用户造成的并发请求,但是也能锁住不同用户的并发请求啊!来举个例子:
小明正在下单一件商品、小红正在提现余额、小李正在充值余额……
这三个用户的操作,是不是都会涉及到“修改账户表余额”的动作?所以问题就来了,小明下单需要获取全局锁、小红提现也需要获取全局锁、小李充值还需要获取全局锁……
可一把锁,同时只能由一个请求(一条线程)持有啊,假设这里小明拿到了锁,那么小红、小李都需要阻塞等待,这合理吗?并不合理,因为小明修改自己的余额,压根不会对小红、小李的余额产生影响。如今这样实现,严重的情况下,会导致整个系统全部夯住。
说人话:小明拿到锁后,小红、小李的网页,都会一直不停的转圈圈,因为在等待锁……
好了,也正是因为这个原因,所以我又补充了一句:

全局锁必须得用,如果不用肯定无法解决并发问题,不过要控制好全局锁的粒度,不能让所有用户抢一把锁!那如何控制锁的粒度呀?大家思考一下。
思考一分钟……
2.2、Redis分布式锁
OK,有人或许会想到:可以用Redis来实现分布式锁呀!然后以用户ID作为Key,以此实现不同的用户,获取不同的全局锁!就像下面这样:
// redis分布式锁伪代码,参数为:key、value、超时时间
redis.set("当前请求的用户ID","xxx","10s");没错,Redis分布式锁确实能完美的解决问题,所以大家看我上面截图的最后一句:

来看看小帅的回答:

“没”,一个特别干脆明了的回答,有人可能会拍桌子:“没Redis还做什么商城项目啊”!还是那句话:

好了,大家继续思考,如果没有Redis,如何控制全局锁的粒度?
思考一分钟……
思考两分钟……
有没有想到?没想到的话接着往下看!
既然是个单体项目,而且还没有Redis,分布式锁就用不上,现在必须得用单机锁来解决,有什么单机锁支持细粒度嘛?经验足够丰富的小伙伴,应该能联想到MySQL行锁、乐观锁!
2.3、MySQL行锁、乐观锁
既然是操作数据表引起的问题,那如果让每次update语句加锁,多条线程并发update时,阻塞其他线程只让单条线程执行,是不是就能实现细粒度的锁,以此达到精准并发控制的目标呢?来试试看:
-- 乐观锁
update
zz_account
set
balance = balance - 100(这里写具体要修改的金额), .......
where
version = version + 1;
-- 行锁(独占式行锁)
update
zz_account
set
balance = balance - 100(这里写具体要修改的金额), .......
for update; -- 行锁PS:如果对MySQL锁机制还不熟悉的小伙伴,可以参考《MySQL锁机制详解》。
来看现在的方案,这样能解决问题吗?还不能,假设余额100,目前有下单-99、提现-2两个操作,虽说有行锁、乐观锁来阻塞另一个操作执行,但另一个操作早晚会执行,依旧会把账户余额扣到-1元。怎么才能确保另一个阻塞的操作,在重新获得执行权、余额不足时,不再执行呢?这里得用到状态机,什么是状态机这个问题,大家可以参考《被登录/注册吊打日记-多IP并发操作问题》的内容。
在咱们如今的例子中,状态机字段不需要额外设计,而是使用balance余额字段即可:
-- 乐观锁+状态机
update
zz_account
set
balance = balance - 100, .......
where
version = version + 1 and balance = [修改前的余额];
-- 行锁+状态机
update
zz_account
set
balance = balance - 100, .......
where
balance = [修改前的余额]
for update;也就是多加了一个where条件:balance=[修改前的余额],还是前面那个举例,假设下单-99这个操作先拿到锁,提现-2这个操作就会阻塞;当下单操作执行完成后,余额会变成100-99=1元;接着提现操作拿到执行权,可是在执行时,会发现余额并不是起初的100元了,因此提现的update语句不能满足条件,最终无法执行。
好!问题再次以完美的形态解决了,可是来看下面这幕:

小帅用的是MyBatis-Plus!不是MyBatis,所以很多数据库操作,都是直接用MP的快捷方法来编写的,并且MP不支持行锁,只支持乐观锁(不过MySQL默认会对写操作加行锁)。
虽说现在这种方式可以解决问题,而且也是最好的方案,但因为代码量和其他方面的原因(主要是业务和表结构),造成这个方案又被搁浅了~
兜兜转转,又得回到ReetrantLock、synchronized、……这些Java单机锁,而传统的单机锁,似乎不支持更细粒度呀?为此需要我们额外拓展,接着来说说。
2.4、细粒度的ReetrantLock全局锁
先来说说基于ReetrantLock做拓展,这需要自己维护一个Map锁容器,如下:
public class IdLockUtils {
// 定义一个全局的锁容器
private static Map<String, Lock> lockMap = new ConcurrentHashMap<>();
// 拓展获取锁方法
public static void lock(String id){
// 先根据id往容器里添加一把锁
lockMap.putIfAbsent(id, new ReentrantLock());
// 再根据id从容器里拿锁并加锁
lockMap.get(id).lock();
}
// 拓展释放锁方法
public static void unlock(String id){
// 先根据id从容器中找到锁
Lock lock = lockMap.get(id);
// 接着使用lock对象释放锁
lock.unlock();
}
}这里定义了一个全局锁容器,为了保证线程安全,这里使用了ConcurrentHashMap作为锁容器保证安全,key在我们这次的例子里,就是账户ID,而value则是一个Lock对象。紧接着拓展了lock/unlock两个方法,unlock()释放锁的代码很简单,诸位自行看注释吧,重点说说获取锁的lock()方法。
在lock()方法中,使用了putIfAbsent()方法往锁容器中,添加一个与id对应的锁对象,put、putIfAbsent两个方法的区别在于:
- put():如果容器中不存在就插入,如果存在则替换;
- putIfAbsent():如果容器中不存在就插入,如果存在则获取已有对象返回。
总之,经过这一步后必然会有一把与id对应的锁,接着通过id拿到了对应的锁,并用这把锁完成了加锁动作(如果一个id对应的锁,已经有线程持有,那么当前线程就会阻塞等待)。
经过这样一番拓展,咱们就能得到支持细粒度的ReentrantLock锁,使用方式如下:
// 获取锁
IdLockUtils.lock("xxx");
// 释放锁
IdLockUtils.unlock("xxx");不过目前有两个问题:
①如果一个用户创建的锁就用过一次,后续该用户再也没登录过平台,相应的锁对象,会一直在内存中存活,这等价于发生了“内存泄漏”。为此,想要设计好这个细粒度的锁,还需要实现定时清理+淘汰策略。
②锁容器为了线程安全,使用了ConcurrentHashMap,在《并发容器-锁分段容器剖析》中聊过,虽然ConcurrentHashMap在1.7之后做过优化,可最终的底层还是会依赖于synchronized,所以在些许特殊情况下,使用lockMap或许要加两层锁。
那咱们能不能直接用synchronized实现细粒度的全局锁呢?答案是可以的,怎么做呀?下面来聊聊。
2.4、细粒度的Synchronized全局锁
大家都知道,synchronized是基于对象上锁的,而Java语言中万事万物皆对象,那有没有一种特殊的对象,能帮我们实现更细粒度的synchronized锁呀?每次直接new新对象行不行?不行,如果每个请求都new新对象,那么每条线程持有各自的锁,依旧会出现并行执行。
各位好好想想,Java里有没有某种特殊的对象呢?等等,String!!!
来看个例子:
String s1 = "竹子";
String s2 = "熊猫";
String s3 = "竹子";
System.out.println(s1 == s2);
System.out.println(s1 == s3);
// --------运行结果--------
false
true==是比较地址,此时s1、s2相比较,结果是false理所当然。可看来s1、s3的对比结果,竟然是true,这是什么原因造成的呢?想要弄明白这个问题,就必须得聊到JVM的知识了。
诸位应该听说过“字符串常量池”这个名词,不过随着JDK的更新,它的位置也一直在变:

在1.7及之后的JDK中,字符串常量池挪到了堆中,为什么要挪动呢?JDK1.7之前,有个永久代空间名为方法区,所谓永久代,即是指里面的数据会从程序启动到终止时,才会释放所占用的空间,而之前的字符串常量池,也位于这块区域里面!字符串常量池会随着程序运行,不断变大,最终把整个方法区撑满。
方法区满了之后怎么办?为了保证程序正常运行,只能在方法区里发生GC,可是方法区的定位是“永久代”,意味着不需要回收,但没办法,方法区满了总不能不管吧?所以JVM又给方法区设计了一种PermGenGC,专门针对方法区进行垃圾回收。
大家看上面这个过程,方法区通常不会撑满,如果触发了GC,多半是由于字符串常量池导致的,所以JDK1.7时干脆一不做二不休,直接把字符串常量池丢到了堆空间,此后字符串常量池会像普通对象一样参与垃圾回收。
其实到了JDK1.8,用元空间代替方法区时,还把静态变量池丢到了堆空间,原本针对方法区设计的PermGenGC,因为可能导致GC的两玩意儿都不在了,所以元空间就没有继续保留这种GC,如果某一天元空间满了,只会触发FullGC来进行回收。
好了,回归正题,既然JVM里有个字符串常量池,它是干啥用的?简单来说,就是用来存储相同的字符串,示意图如下:

当定义两个值为“竹子”的变量s1、s2时,这时并不会在内存中挖两个坑,然后埋进去两个竹子,而是去字符串常量池里找一找,看看有没有“竹子”这个字面量,如果已经存在,直接把s1、s2的指针指向常量池里的“竹子”。如果没找到,就先在常量池里创建一个“竹子”,然后再修改s1、s2的指针。
讲到这里,前置知识就已经足够了,咱们如何基于这些特性,实现细粒度的synchronized全局锁呢?很简单,既然String也是对象,那咱们能不能基于它来作为锁对象?当然可以,如下:
// 定义锁对象
String lock = "竹子爱熊猫";
// 基于String对象上锁
synchronized (lock){
// .......
}结合前面的ID思想,咱们能不能像下面这样做?下面写个伪代码:
// 提现方法
public static void cashWithdrawal(String accountId){
// 使用传入的id作为锁对象
synchronized (accountId){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行提现逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
// 下单方法
public static void placeAnOrder(String accountId){
// 使用传入的id作为锁对象
synchronized (accountId){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行下单逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
public static void main(String[] args) {
// 用三条线程模拟并发调用
new Thread(() -> cashWithdrawal("123456"), "AAA").start();
new Thread(() -> placeAnOrder("123456"), "BBB").start();
new Thread(() -> cashWithdrawal("666666"), "CCC").start();
}上面写了提现、下单两个方法,两个方法都要求外部传入一个accountId,稍后会以这个ID作为锁对象。在下面的测试中,创建了AAA、BBB、CCC三条线程:
- AAA调用提现方法,传入ID=123456;
- BBB调用下单方法,传入ID=123456;
- CCC调用提现方法,传入ID=666666。
从上述调用情况来看,AAA、BBB因为传入的ID相同,说明这是共一个用户造成的并发请求,而CCC传入的ID=666666,说明这是另一个用户在提现,此时来看运行结果:

OK,是不是能够实现咱们的需求?按ID进行细粒度的并发控制,只有相同用户的并发请求才会阻塞,不同用户的并发请求不会有任何影响。那也许有人会问,我id是Long类型的咋办?这很简单呀,直接123456L + ""转换一下即可。
好了,问题似乎大功告成,大家看到这里,是不是以为就结束了?不,这才是刚刚开始呢~
三、字符串作为锁对象的坑
经过小帅不懈努力,终于把每个涉及到“修改的余额”的业务方法,加上了细粒度的synchronized,可是来看他给的回复:

3.1、问题现场恢复
修改、打包、启动、测试,哦豁!发现方案不太行,为啥呀?来看它给我截图的代码:

因为他的uid是long类型,无法基于字符串常量池实现全局锁,为此要先将Long转为String,才能继续进行加锁操作,不过上述截图看的不是很清晰,抛开业务逻辑,我将其做了精简:
// 提现方法
public static void cashWithdrawal(Long accountId){
String lock = accountId + "";
// 使用传入的id作为锁对象
synchronized (lock){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行提现逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
// 下单方法
public static void placeAnOrder(Long accountId){
String lock = accountId + "";
// 使用传入的id作为锁对象
synchronized (lock){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行下单逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
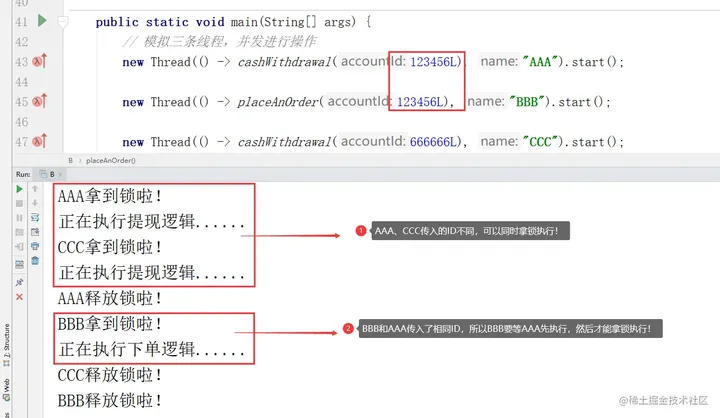
public static void main(String[] args) {
// 模拟三条线程,并发进行操作
new Thread(() -> cashWithdrawal(123456L), "AAA").start();
new Thread(() -> placeAnOrder(123456L), "BBB").start();
new Thread(() -> cashWithdrawal(666666L), "CCC").start();
}代码很上一次对比,并未出现太大变化,仅仅只是修改了方法入参类型,而后在方法内部将Long转为了String,而后再进行加锁工作,可是就是这一点细微变化,执行结果却大不相同:

看这个执行结果,大家应该能够看的十分明白,将代码改成上述那样后,两个传递传递相同的ID的线程,竟然同时拿到了锁,也就是锁不住了!为啥啊?再来看个例子:
// 提现方法
public static void cashWithdrawal(String accountId){
// 使用传入的id作为锁对象
synchronized (accountId){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行提现逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
// 下单方法
public static void placeAnOrder(String accountId){
// 使用传入的id作为锁对象
synchronized (accountId){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行下单逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
public static void main(String[] args) {
// 模拟三条线程,并发进行操作
new Thread(() -> cashWithdrawal(123456L+""), "AAA").start();
new Thread(() -> placeAnOrder(123456L+""), "BBB").start();
new Thread(() -> cashWithdrawal(666666L+""), "CCC").start();
}这里又将入参改回了String类型,此时在外部先将Long转成String,而后再调用业务方法,再来看看结果:

很好,此时细粒度的锁又生效了,Why?凭什么在外部转换类型就生效,在方法里面转换就失效啊?此时小小的脑袋里有着大大的疑惑……。为了更好的搞清楚背后原因,就先讲明白:为什么基于相同字符串,就可以做到细粒度的并发控制呢?
3.2、字符串实现细粒度锁的原理
先回到之前的这幅图:
前面讲过,如果两个字符串变量,定义的字面量相同,最终都会指向字符串常量池中的同一个地址,这个地址上存放着一个String对象。以上图为例,假设这里使用s1、s2进行加锁:
synchronized (s1) { ...... }
synchronized (s2) { ...... }加锁的过程是什么样子的?经过《Synchronized原理》讲述,大家应该能得知一点,synchronized关键字是基于对象头实现的锁机制。那么在上面的例子中,首先会根据s1、s2指针,找到字符串常量池中的某个地址,然后得到String("竹子")这个对象。
因为s1、s2都指向同一个String对象,为此,当有多条线程同时使用s1、s2获取锁时,最终也就只会有一条线程获取锁成功,其余线程都陷入阻塞等待。
上述便是细粒度synchronized锁的原理,一句话总结就是:这是基于字符串常量池,相同的字面量只会存在一个String对象来实现的。理解这些原理后,接着再看小帅目前碰到的问题。
3.3、分析类型转换产生的问题
public static void xxx(Long accountId){
String lock = accountId + "";
synchronized (lock){
......
}
}将类型转换放在方法内部完成,从而引发了新的问题:传入相同ID的线程锁不住。经过前面一番推敲后,其实就能大致得到该问题的产生原因:应该是在方法内部转换时,产生了新的String对象,所以两个不同的方法中,各自基于各自的String对象上锁,最终诱发了问题。究竟是不是这个原因,咱们还需做番实验:
public static void xxx(Long accountId){
String idLock = accountId + "";
String s1 = "123456";
String s2 = "123456";
System.out.println("idLock:" + idLock);
System.out.println("s1:" + s1 + "、s2:" +s2);
System.out.println(s1 == s2);
System.out.println(idLock == s1);
}
public static void main(String[] args) {
xxx(123456L);
}这个代码相信特别容易读懂,定义了一个xxx方法,该方法接受一个Long类型的入参。
调用xxx()方法时传入了123456这个Long值,接着在方法内部将其转换成了String类型的idLock变量;随即又定义了两个s1、s2字符串变量,接着将三个变量的值输出了,最后在三个变量之间进行了==比对,来看结果:
// --------运行结果--------
idLock:123456
s1:123456、s2:123456
true
false三个字符串变量的值都为123456,s1==s2的结果为true,说明它俩是同一个String对象,而idLock==s1对比后的结果为:false!这说明什么?说明idLock是另一个String对象!!!其实这行转换代码:
String idLock = accountId + "";就和八大基本数据类型一样,同样存在类似的拆/装箱机制,实际的完整代码为:
String idLock = new String(accountId + "");这样就创建出了一个新的String对象,因为new的String对象,不会去字符串常量池里找,而是直接分配到堆空间上,视作为一个普通类型的对象,如何证明呢?看个例子:
String s1 = new String("竹子");
String s2 = new String("竹子");
System.out.println(s1 == s2);上述这段代码,虽说s1、s2的字面量相同,但由于使用了new形式来创建,所以最终的运行结果为false,这说明s1、s2是两个不同的对象了。
到这里,相信大家就明白了小帅为什么会遇到“锁不住”的问题,就是因为方法内部转换类型时,会触发类似于“装箱机制”的操作,将转换后的String对象分配到堆空间,而不是从字符串常量池中查找。
不过值得一提的是:只有在一个被调用方法的内部,对方法入参进行String类型转换时,才会触发这个“装箱机制”,再来看个例子:
public static void main(String[] args) {
String s1 = 123L + "";
String s2 = 123L + "";
System.out.println(s1 == s2);
}这时我直接在main方法中,将两个Long值123转换为s1、s2后,再使用==来对比,结果竟然又成了true,说明s1、s2又指向了字符串常量池中的同一个String对象,这是不是挺神奇的~
3.4、解决类型转换带来的问题
OK,问题产生的原因搞明白之后,咱们得想办法解决问题呀!咋解决呢?既然问题是因为“在方法内部转换类型时,会将转换后的String对象分配到堆空间”产生的,那咱们是不是只要想办法,让这个类型转换后生成的String对象,再次回到字符串常量池,是不是就可以啦?
答案是Yes,可又该如何把转换后的String对象,从普通堆空间丢到字符串常量池里面去呢?答案是String.intern()方法!这个方法研究过JVM的小伙伴应该接触过,作用如下:
new一个String对象时,调用intern()方法,首先会去字符串常量池找;
如果在字符串常量池中,找到了相同字面量的String对象,此时返回该对象的引用地址;
如果字符串常量池中,没有相同字面量的String对象时,就把当前new的String对象加入到字符串常量池,而后返回该对象的引用地址。
简单来说,这个方法的作用就是:new之前先去常量池转一圈,如果已经有同样的对象,我就拿着直接用;如果没有,我就在池子创建一个,以后别人也可以用。
理解该方法的作用,我们就可以借助该方法实现我们的需求,代码如下:
// 提现方法
public static void cashWithdrawal(Long accountId){
String lock = new String(accountId + "").intern();
// 使用传入的id作为锁对象
synchronized (lock){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行提现逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
// 下单方法
public static void placeAnOrder(Long accountId){
String lock = new String(accountId + "").intern();
// 使用传入的id作为锁对象
synchronized (lock){
System.out.println(Thread.currentThread().getName() + "拿到锁啦!");
System.out.println("正在执行下单逻辑......");
try {
// 模拟业务耗时
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "释放锁啦!");
}
}
public static void main(String[] args) {
// 模拟三条线程,并发进行操作
new Thread(() -> cashWithdrawal(123456L), "AAA").start();
new Thread(() -> placeAnOrder(123456L), "BBB").start();
new Thread(() -> cashWithdrawal(666666L), "CCC").start();
}上述代码依旧是没做太大改动,方法的入参依旧是Long,仅仅换了一行代码:
String lock = accountId + "";
// 替换成:
String lock = new String(accountId + "").intern();这时再来看最终的执行结果:
好啦,到这里真正大功告成!问题自此完美解决!剩下只需将这个思想,套入到具体的业务中即可。
四、总结
有人或许会说:“用Synchronized不是很慢吗?”
其实经过JDK的不断优化,如今的synchronized只要未膨胀到重量级锁,性能反而更好(因为有偏向锁和锁消除技术);同时这里还以ID作为了锁对象,几乎很少有相同ID的并发请求出现,所以每个不同用户的请求,都会获取一把各自的锁,相互之间并不干扰,也不会造成阻塞现象发生。
有人可能还会问:“可是创建这么多的String对象,不会把内存撑爆吗?”
首先呢要记住,这里的锁对象,是使用了系统内本身就存在的用户ID、账户ID……,就算不以这些ID作为锁对象,内存中依旧会存在这些String对象,所以咱们并没有额外增加内存的负担,只不过把String对象换了个位置而已,放到字符串常量池里面去了。
其次呢,synchronized重量级锁会生成Monitor对象,可是咱们这个场景下,synchronized压根膨胀不到重量级锁状态,毕竟前面讲过,这里的每把锁,大概率下只会有一条线程竞争。
最后呢,由于官方已经把字符串常量池丢到堆空间来了,所以字符串常量池中的String对象,同样会参与堆空间的垃圾回收,所以也不用担心内存爆掉,JVM的垃圾回收系统,会妥善帮你处理好这个问题。除非你的系统有千万级在线用户,导致字符串常量池出现1000W个对象,一下又无法回收,最终OOM(不过能达到千万日活的系统,谁又会用单体架构呢~)。